Глава 6. Этапы развития зрения.
Неокогнитрон и конволюционные нейронные сети
Проект "Летнее зрение" - это попытка эффективно использовать наших летних сотрудников для построения значительной части зрительной системы. Конкретная задача была выбрана отчасти потому, что ее можно разделить на подпроблемы, которые позволят людям работать независимо и при этом участвовать в создании достаточно сложной системы, чтобы стать настоящей вехой в развитии "распознавания образов".
Vision Memo No. 100 из группы искусственного интеллекта Массачусетского технологического института, 1966 г.
Лето 1966 года должно было стать летом, когда группа профессоров Массачусетского технологического института решила проблему искусственного зрения. В качестве "летних работников", которых они планировали эффективно использовать для этого проекта, выступала группа из дюжины или около того студентов-бакалавров университета. В своей записке, излагающей план проекта, профессора указали несколько конкретных навыков, которые должна была выполнять компьютерная система, разрабатываемая студентами. Она должна уметь определять различные текстуры и освещение на изображении, обозначать части изображения как передний план, а части как фон, и идентифицировать любые объекты. Один из профессоров якобы описал цели более упрощенно: "Подключить камеру к компьютеру и заставить компьютер описать то, что он видит".
Цели этого проекта не были достигнуты тем летом. Ни следующим. И многие последующие. Более того, некоторые из основных вопросов, поднятых в описании летнего проекта, остаются открытыми проблемами и по сей день. Спесь, проявленная в этом меморандуме, не удивительна для своего времени. Как уже говорилось в главе 3, 1960-е годы ознаменовались бурным ростом вычислительных возможностей и, в свою очередь, наивными надеждами на автоматизацию даже самых сложных задач. Компьютеры теперь могли делать все, что от них требовалось, нужно было только знать, о чем просить. А если речь идет о чем-то столь простом и непосредственном, как зрение, насколько это сложно?
Ответ очень сложен. Процесс обработки зрительного сигнала - восприятия света глазами и осмысления отраженного в нем внешнего мира - чрезвычайно сложен. Распространенные поговорки вроде "прямо перед глазами" или "на виду", которые используются для обозначения легкости зрения, обманчивы. Они затушевывают значительные трудности, с которыми сталкивается мозг при восприятии даже самых простых зрительных объектов. Любое чувство легкости, которое мы испытываем в отношении зрения, - это иллюзия, с трудом завоеванная миллионами лет эволюции.
Проблема зрения - это проблема обратной инженерии. В задней части глаза, в сетчатке, широкий плоский лист клеток, называемых фоторецепторами. Эти клетки чувствительны к свету. Каждая из них указывает на наличие или отсутствие (и, возможно, длину волны) света, попадающего на нее в каждый момент времени, посылая сигнал в виде электрической активности. Эта двумерная мерцающая карта клеточной активности - единственная информация, на основе которой мозг может воссоздать трехмерный мир перед собой.
Даже такое простое дело, как поиск стула в комнате, представляет собой технически сложную задачу. Стулья могут быть самых разных форм и цветов. Они также могут находиться рядом или далеко, что делает их отражение на сетчатке глаза больше или меньше. Светло в комнате или темно? С какого направления падает свет? Кресло повернуто к вам или от вас? Все эти факторы влияют на то, как именно фотоны света попадают на сетчатку. Но триллионы различных световых картин в итоге могут означать одно и то же: стул на месте. Зрительная система каким-то образом находит способ решить эту проблему сопоставления многих и одного менее чем за десятую долю секунды.
В то время, когда студенты Массачусетского технологического института работали над тем, чтобы подарить зрение компьютерам, физиологи использовали свои собственные инструменты, чтобы разгадать тайны зрения. Началось все с регистрации нейронной активности сетчатки глаза, а затем нейроны перешли к нейронам всего мозга. Поскольку, по оценкам, 30 процентов коры головного мозга приматов играет ту или иную роль в обработке зрительных сигналов, это было немалым делом.2В середине XX века многие ученые, проводившие эти эксперименты, базировались в Бостоне (многие в самом Массачусетском технологическом институте или чуть севернее, в Гарварде), и у них быстро накапливался большой объем данных, которые нужно было как-то осмыслить.
Возможно, дело в физической близости. Возможно, это было молчаливое признание огромной задачи, которую каждый из них поставил перед собой. Возможно, на первых порах сообщества были слишком малы, чтобы держаться в тени. Какова бы ни была причина, неврологи и компьютерные ученые долгое время сотрудничали в попытках понять фундаментальные вопросы зрения. Изучение зрения - того, как можно найти закономерности в световых точках, - наполнено прямым влиянием биологического на искусственное и наоборот. Гармония, возможно, не была постоянной: когда компьютерная наука начала использовать методы, которые были полезны, но не напоминали мозг, области разошлись. А когда нейробиологи вникали в мельчайшие детали клеток, химических веществ и белков, обеспечивающих биологическое зрение, компьютерщики в основном отворачивались. Но последствия взаимного влияния по-прежнему неоспоримы и хорошо видны в самых современных моделях и технологиях.
* * *
Первые попытки автоматизировать зрение появились еще до появления современных компьютеров. Хотя они были реализованы в виде механических приспособлений, некоторые идеи, лежавшие в основе этих машин, подготовили поле для последующего появления компьютерного зрения. Одной из таких идей был подбор шаблонов.
В 1920-х годах Эмануэль Гольдберг, русский химик и инженер, решил проблему, с которой столкнулись банки и другие офисы при поиске документов файловых системах. В то время документы хранились на микрофильмах - полосках 35-миллиметровой пленки, содержащих крошечные изображения документов, которые можно было проецировать на большой экран для чтения. Порядок расположения документов на пленке был мало связан с их содержанием, поэтому поиск нужного документа - например, аннулированного чека конкретного клиента банка - был связан с неструктурированным поиском. Чтобы автоматизировать этот процесс, Голдберг прибег к грубой форме "обработки изображений".
Согласно плану Голдберга, кассиры, вносящие новый чек в систему учета, должны были пометить его специальным символом, указывающим на его содержание. Например, три черные точки в ряду означали, что имя клиента начинается с буквы "А", три черные точки в треугольнике - что с буквы "Б" и так далее. Теперь, если кассир хотел найти последний чек, предъявленный, например, мистером Беркширом, ему нужно было просто найти чеки, помеченные треугольником. Таким образом, шаблон треугольника был шаблоном, и задача машины Голдберга состояла в том, чтобы соответствовать ему.
Физически эти шаблоны имели форму карточек с пробитыми в них отверстиями. Так, при поиске документов мистера Беркшира кассир брал карточку с тремя отверстиями в форме треугольника и помещал ее между лентой микрофильмов и лампочкой. Затем каждый документ на ленте автоматически подтягивался к карточке, в результате чего свет проникал через отверстия на карточке, а затем и через саму пленку. Фотоэлемент, расположенный за пленкой, фиксировал любой проходящий свет и сигнализировал об этом остальным частям машины. Для большинства документов свет проникал через пленку, так как символы на пленке не совпадали с отверстиями на карте. Но когда появлялся нужный документ, свет, проникающий через карточку, полностью блокировался узором из черных точек на пленке. Эти мини-затмения означали, что свет не попадает на фотоэлемент, и это сигнализировало остальным частям машины и кассиру, что совпадение найдено.
Подход Голдберга требовал, чтобы кассиры заранее знали, какой именно символ они ищут, и имели карту, соответствующую ему. Несмотря на свою грубость, этот стиль подбора шаблонов стал доминирующим подходом на протяжении большей части истории искусственного зрения. Когда на сцене появились компьютеры, форма шаблонов перешла из физической в цифровую.
В компьютере изображение представлено в виде сетки значений пикселей (см. рис. 14). Каждое значение пикселя - это число, указывающее на интенсивность цвета в крошечной квадратной области изображения, которую оно представляет.3 В цифровом мире шаблон - это тоже просто сетка чисел, определяющая нужный шаблон. Так, шаблон для трех точек в форме треугольника может представлять собой сетку, состоящую в основном из нулей, за исключением трех точно расположенных пикселей со значением 1. В машине Голдберга роль света, проходящего через карточку-шаблон, в компьютере была заменена математической операцией: умножением. Если значение каждого пикселя на изображении умножить на значение в том же месте шаблона, результат может сказать нам, совпадает ли изображение.
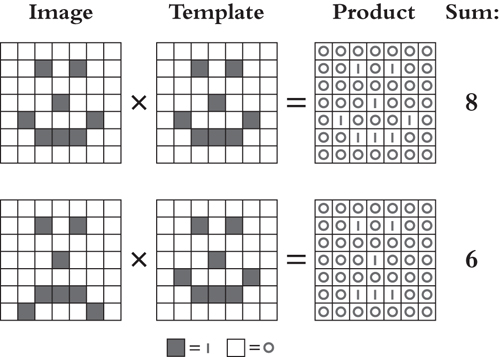
Рисунок 14
Допустим, мы ищем улыбающееся лицо на черно-белом изображении (где черные пиксели имеют значение один, а белые - ноль). Имея шаблон лица, мы можем сравнить его с изображением путем умножения. Если на изображении действительно изображено искомое лицо, то значения, составляющие шаблон, будут очень похожи на значения на изображении. Поэтому нули в шаблоне будут умножены на нули в изображении, а единицы в шаблоне - на единицы в изображении. Сложив все полученные в результате умножения значения, мы получим количество черных пикселей, одинаковых в шаблоне и на изображении, которых в случае совпадения будет много. Если на полученном нами изображении будет хмурое лицо, то некоторые пиксели вокруг рта на изображении не будут совпадать с шаблоном. Там нули в шаблоне будут умножены на единицы в изображении, и наоборот. Поскольку произведение в этих местах пикселей будет равно нулю, сумма по всему изображению не будет такой большой. Таким образом, простая сумма произведений дает представление о том, насколько изображение соответствует шаблону.