До сих пор речь шла лишь о равноправных, равновероятных исходах. Если брать падение монеты или кубика, то это будет так. Но большинство выборов неравновероятны. Например, в вашем классе единицы и двойки — явление гораздо менее частое, чем пятерки или четверки. Температура ниже нуля — обычное явление в январе и очень редкое в июле. Слово «целую» и «приезжаю» можно встретить почти в любой телеграмме, а чтобы найти слова «сумма синусов», вам, вероятно, пришлось бы пересмотреть не одну тысячу телеграмм.
Как же быть с такими событиями, «равновероятными» кодовыми знаками? До Шеннона считалось, что измерить количество информации, которое несут эти знаки, нельзя. Ведь вероятность хорошей или плохой оценки зависит от успеваемости в классе, от того, насколько хорошо выучен урок, а не от математики. Точно так же и погода, и телеграммы, посылаемые с почтамта, и многие другие «неравновероятные» события.
Клод Шеннон показал, что с помощью теории вероятностей можно учесть и эти причины, казалось бы, совершенно не «подведомственные» математике. Например, если в классе из 100 отметок по физике 65 — пятерки, 22 — четверки, 9 — тройки, 4 — двойки и ни одной единицы, можно считать, что вероятность получения «отлично» равна 0,65, «хорошо» — 0,22, «посредственно» — 0,09, «плохо» — 0,04, «очень плохо» — 0,00.
Зная эти вероятности, можно найти количество информации, которое получает классный руководитель, узнавая об успеваемости по физике.
Давайте посчитаем сами. Всего возможно пять разных оценок, пять различных исходов. Двоичный логарифм 5 равен 2,32193. Но все оценки, как мы говорили, имеют разную вероятность. Ученик, скорее всего, получит 5 или 4, а не 3 или 2. Учитывая разную вероятность этих оценок, по формуле Шеннона можно найти количество информации более точно. Оно равно вероятности первой оценки (пятерки), умноженной на двоичный логарифм вероятности этой же оценки, плюс вероятность второй оценки, умноженной на двоичный логарифм вероятности этой же оценки,
и т. д.
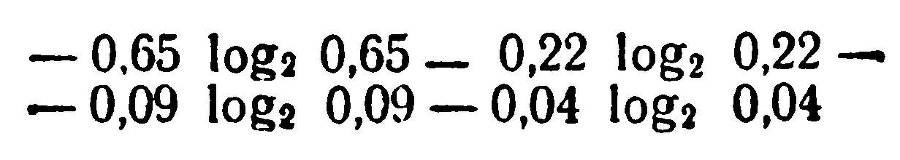
В итоге получается 1,3831 бита двоичных единиц информации. Почти в два раза уменьшилось количество информации, когда мы учли «неравноправие» различных выборов!
Формула Шеннона может помочь найти количество информации при любом числе выборов. Лишь бы нам была известна вероятность их появления. А вероятность эту можно определить, производя статистические подсчеты.
Погода не зависит от математики. Но если вести регулярные и многолетние наблюдения, можно знать, как часто бывают в данной местности дождь, засушливые дни, заморозки, иными словами — «вероятность появления» дождя, заморозков, засушливых дней.
С помощью формулы Шеннона можно найти и количество информации, которое несет одна буква письменной речи. А ведь зная это, легко высчитать, сколько битов информации содержится в любом печатном тексте.
БИТЫ И БУКВЫ
В русском языке 33 буквы. Двоичный логарифм числа 33 равен 5,04439.
Значит, одна буква русского языка несет примерно 5,04 бита информации.
Буквы «е» и «ё» обычно принято считать одной буквой. В одну букву можно объединить твердый и мягкий знаки. А промежуток между словами, «пробел», наоборот, можно причислить к буквам. В итоге — 32 буквы, 32 кодовых знака.
Двоичный логарифм 32 равен 5. Значит, 5 бит информации несла бы буква, если бы все буквы нашего языка одинаково часто встречались в словах. Однако это далеко не так.
Средняя длина русского слова 5—6 букв. Значит, пробел, разделяющий слова, будет встречаться очень часто. Было подсчитано, что в тексте из 1000 букв пробел встречается в среднем 175 раз.
Зато буква «х» в тексте из 1000 букв будет встречаться 9 раз, «ш» и «ю» — по 6 раз, «щ» и «э» — по 3 раза, «ц» — 4 раза, «ф» — 2 раза. Чаще же всего после «нулевой буквы» — пробела, будет встречаться буква «о» — 90 раз, затем «е» вместе с «ё» — 72 раза, буквы «а» и «и» — по 62 раза каждая.
Из-за того, что буквы языка «неравноправны», одни встречаются очень часто, другие — редко, третьи — очень редко, информация, которую несет одна буква нашего языка, уменьшается с 5 бит до 4,35.
Но ведь с различной частотой встречаются и различные сочетания букв.
Например, «ж» или «и» в сочетании с буквой «ы» в грамотно написанном тексте не встретится ни разу, какой бы длинный отрезок его мы ни брали. Недаром мы учим: «жи», «ши» пиши через «и».
Точно так же не встретим мы сочетания трех букв «и» или четырех «е» (да и три буквы «е» подряд имеются лишь в очень немногих русских словах — «длинношеее», «змееед»).
Число русских слов ограниченно, хотя и очень велико. Не каждое сочетание букв образует слово. Математики даже подсчитали, что только две десятитысячных процента сочетаний букв образуют русские слова. Из миллиона сочетаний только два пригодны быть словами!
Кроме того, не всякие сочетания русских слов могут образовывать текст. Во-первых, они должны подчиняться правилам грамматики. Нельзя говорить «мы пошел лес в» или «я буду купил марки иностранную». А во-вторых, и это самое важное, речь должна быть осмысленной.
Передача смысла — главная цель человеческого общения.
А какой может быть смысл в фразе, хотя и соблюдающей правила грамматики, вроде «тщеславие яблока сомневалось в безумном разуме стула»?
Если бы наша речь была беспорядочным набором букв вроде ъбьроапришенгтраствстькаепр, одна буква русского языка несла бы 5 бит информации. Осмысленная же речь сокращает это количество в пять раз. Как показали опыты, буква русского языка несет не пять, а всего лишь 1 бит информации.
ЗАПАС ПРОЧНОСТИ» ЯЗЫКА
Почему же бессмысленный набор букв несет в пять раз больше информации, чем осмысленный текст? Как же это так получается?
Дело в том, что мы измеряем количество информации, а не ее смысл. С помощью формулы Шеннона мы вычисляем в битах «степень незнания», которую уничтожают получаемые нами кодовые знаки — буквы. Разумеется, наше незнание гораздо больше, когда мы принимаем беспорядочный набор букв вроде ъапроатшезщбльоцнстьнронрб, а не осмысленную речь. Мы не знаем, какая буква будет следующей в этом наборе. А в осмысленной речи легко догадаться, что после слов «он учится только на пять, он круглый...» последует слово «отличник», что после букв «учительн...» последует окончание «ица», или «ицы», или «ицей», но никак не «ая» или «ой».
Вот и получается, что по количеству «уничтожаемого незнания» бессмыслица стоит выше, чем осмысленный текст.
Конечно, в будущем ученые смогут измерять не только общее количество информации, но и величину смысла. Правда, сделать это невероятно трудно: слишком сложен наш человеческий язык, чтобы выразить в числах не только кодовые знаки, но и смысл сообщения.
И еще более трудно определить ценность информации.
В книге из 10 тысяч букв содержится 10 тысяч бит информации. Вполне может случиться, что вы эту книгу читали и даже знаете наизусть. Ваш приятель читал ее давно и поэтому плохо помнит. А другой приятель вообще первый раз в жизни слышит о ней. Сколько же информации получит каждый из вас?
Если мерять количество информации, то, разумеется, оно будет одинаково — 10 тысяч бит. Но вы не получите ровно ничего нового. Первый приятель лишь подновит забытые сведения. А второй и в самом деле получит уйму новых сведений. Разумеется, ценность информации для всех трех различна. Однако попробуйте выразить ее в числах!
Но даже ограниченное измерение информации, без учета ее смысла и ценности, позволяет делать интересные выводы и наблюдения.
Мы уже говорили, что примерно лишь 0,0002 процента всех возможных сочетаний русских букв образуют слова. Почему же такая неэкономия? Нельзя ли сделать так, чтобы каждая буква, каждое сочетание букв было самостоятельным словом? Например, чтобы русскими словами были не только буквы «а», или «я», или «и», но и «з», «п», «м», «ю» или сочетания букв вроде «птп», «мн», «ашяс» и т. д.