
Процесс копирования последовательности ДНК в молекулах РНК принято называть транскрипцией. С принципиальной точки зрения он наименее интересен; если следовать сухой инженерной логике, кажется, что можно обойтись и без него. И в самом деле, есть вирусы, обходящиеся только одним видом нуклеиновых кислот — РНК.
Зато очень важен следующий этап преобразования наследственной информации: РНК ― белок. Если в случае транскрипции речь идет о простом ее переписывании, то здесь более уместно было бы говорить о переводе.
И ДНК и РНК образованы четырьмя типами нуклеотидов, причем для обеих молекул их строение довольно схоже. Следующей же формой записи наследственной информации оказываются молекулы белка — полимера, цепочка которого образована двадцатью различными типами элементарных звеньев.
Молекула белка строится из аминокислот, химических соединений сравнительно простой структуры:
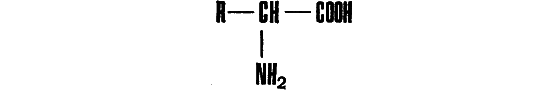
Химические формулы аминокислот мы приводить не будем, а вот названия на всякий случай перечислим:
глицин, аланин, валин, изолейцин, лейцин
серин, треонин, пролин, метионин, цистеин
аргинин, лизин, фенилаланин, тирозин, гистидин
триптофан, аспарагин, аспарагиновая кислота, глутамин, глутаминовая кислота
Разумеется, запоминать их совершенно необязательно, достаточно просто запомнить место в книге, где приведен этот перечень: в дальнейшем, наткнувшись в тексте на одно из таких названий, вы, возможно, захотите убедиться, что речь идет именно об аминокислоте. (Кстати, разрешение не запоминать наизусть названия всех двадцати аминокислот — голубая мечта каждого студента, готовящегося к экзаменам по биохимии. Увы, мечта совершенно неосуществимая.) Каждая пара аминокислот соединяется друг с другом с выделением молекулы воды, и, таким образом, может образоваться цепочка произвольной длины:
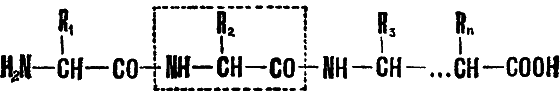
Ее остов имеет регулярную структуру, в которой повторяется один и тот же элемент — так называемая пептидная группа, а привески — боковые радикалы — могут чередоваться в любом порядке. Элементарный фрагмент такой цепочки называется аминокислотным остатком (он выделен штриховой рамкой).
Легко заметить, что при описанном способе построения белковой молекулы на одном ее конце будет свободная аминогруппа — NH2, на другом — карбоксигруппа — COOH. Это означает, что последовательность аминокислотных остатков в белке (так же, как и оснований в ДНК или РНК) направленная, то есть молекулы какой-либо пары аминокислот, например аланина и глицина, можно соединить друг с другом двумя различными способами, так, чтобы в одном из них остаток глицина участвовал в образовании пептидной связи своей аминогруппой, во втором — карбоксигруппой.
Попросим нескольких человек выстроиться в ряд по росту, взявшись за руки; два способа построения — убывание роста слева направо или справа налево — будут принципиально различными. Каждый участник такого построения будет держаться за руку более высокого соседа либо левой, либо правой рукой, и в зависимости от способа построения у самого высокого участника окажется свободной либо левая, либо правая рука. Для придания определенности можно потребовать, чтобы свободной у него оказалась, к примеру, именно правая рука, а у самого низкорослого участника — левая.
Совершенно аналогично аминокислотные последовательности белков принято записывать в направлении от остатка, несущего группу NH2 (называемого N ― концевым остатком), к остатку, несущему карбоксигруппу СООН (С ― концевому остатку).
Нуклеиновые кислоты и белки — полимеры принципиально разной структуры, и сам молекулярный механизм синтеза белковой молекулы на основе инструкции, содержащейся в молекуле РНК, не имеют ничего общего со сравнительно простыми схемами репликации и транскрипции. Он намного сложней, и тем больше чести для исследователей, благодаря которым ныне известны основные принципы его организации. Однако нас пока интересует не этот механизм, а вопрос чисто формального «перевода» РНК-овых последовательностей на язык молекул белка.
Разумеется, нет ничего принципиально невозможного в передаче последовательности символов двадцатибуквенного алфавита последовательностью символов четырехбуквенного алфавита. Вспомним хотя бы азбуку Морзе, с помощью которой набор точек и тире переводится в русский текст (а это вместе с цифрами и знаками препинания около 50 различных символов). Однако азбуку Морзе выдумали люди…
С того момента, как на основании многих тонких и остроумных экспериментов биологам стало ясно, что последовательность аминокислотных остатков в молекуле белка определяется нуклеотидной последовательностью РНК, вопрос о способе кодирования сделался самой злободневной проблемой и для экспериментаторов и для теоретиков. Мы снова воздержимся от исторических экскурсов, ограничившись перечислением фамилий основных героев эпопеи расшифровки генетического кода — американцев М. Ниренберга, С. Очоа и англичанина Ф. Крика. Обратимся лучше сразу к плодам их усилий.
С формальной точки зрения структура генетического кода сравнительно проста. Последовательность нуклеотидов в нити РНК при чтении мысленно подразделим на тройки оснований (именно мысленно, поскольку никаких структурных признаков такого подразделения нет). Тогда, как оказывается, каждой тройке может быть сопоставлен один из двадцати аминокислотных остатков. Общее число всех возможных троек (их называют еще триплетами) — 64 (то есть 4×4×4), так что большинство остатков может кодироваться несколькими способами. Кроме того, есть два особых триплета, которыми обозначаются начало и конец аминокислотного «текста» — белковой молекулы.
Теперь, имея в своем распоряжении кодовую таблицу, можно с легкостью перевести текст РНК-овой последовательности на белковый язык. Более того, будь эта книга учебником, можете не сомневаться, что авторы предусмотрели бы несколько страниц такого перевода в разделе «Самостоятельные упражнения».
По поводу набора аминокислот, образующих белковую молекулу, необходимо сделать еще одно замечание. В различных организмах присутствуют в свободном виде, помимо двадцати перечисленных, еще несколько десятков других аминокислот, также имеющих структурную формулу H2N―CHR―СООН. Многие из них играют очень важную роль в обмене веществ, но ни одна не вовлекается в синтез белка. Точнее, иногда такие аминокислоты встречаются в составе белковой молекулы, однако всегда оказывается, что при «считывании» последовательности белков с РНК в соответствующих положениях присутствуют «нормальные» остатки и лишь впоследствии, уже по завершении синтеза, их боковые радикалы модифицируются.
20 аминокислот, входящих в кодовый словарь, иногда называют «магическим набором». Это название отражает удивление биохимиков «докодового» периода, которые обнаруживали в составе белков лишь часть аминокислот, находящихся в организме в свободной форме. Установление структуры кода указывает, по крайней мере, происхождение именно такого положения вещей, хотя и не объясняет его внутренней целесообразности.
Авторы уже начали ощущать принятый ими темп галопа. Конечно, краткость — сестра таланта, однако излагать в такой вот конспективной форме сведения, составляющие основу и гордость современной молекулярной биологии, не только трудно, но даже и несколько неприятно. Так и тянет отвлечься на какую-нибудь интересную подробность, рассказать, как был осуществлен синтез полифенилаланина на полиурациле (согласно генетическому коду триплету УУУ соответствует остаток фенилаланина), как экспериментальному открытию кода в 1964 году предшествовали темпераментные и очень цветистые дискуссии теоретиков, какими курьезными комментариями сопровождали сообщение об этом открытии некоторые журналы… Словом, массу интересного и даже пикантного материала приходится опускать, предварительно поставив на нем клеймо «для дальнейшего изложения необязателен». Как говорят опытные альпинисты, брать не то, что может пригодиться, а только то, без чего нельзя обойтись.