1. Когда вы хотите Генерировать не сноски, а гиперссылки, а эти гиперссылки в виде цифр в верхнем индексе выглядят не очень эстетично, на ваш взгляд.
2. Когда вы не хотите генерировать ни сноски, ни гиперссылки, а просто хотите преобразовать номера примечаний в верхнем индексе к более удобному для вас виду.
3. и т. д.
3. Интерактивное преобразование номеров примечаний в верхнем индексе по шаблону

Этот инструмент полезен в тех случаях, где нельзя использовать инструмент автоматического преобразования номеров примечаний в верхнем индексе (см. выше) – в документе есть математические формулы со степенями (цифры в верхнем индексе) и т. д. Автоматическое преобразование нельзя использовать в таких книгах, как Библия, Коран, математические книги и т. д., в которых цифры в верхнем индексе обозначают номера стихов (Библия, Коран…) или степень числа в формулах. При использовании автоматического преобразования все эти цифры тоже будут преобразованы по шаблону (например, {1}), а это – неверно.
Поэтому для таких книг и разработан инструмент интерактивного преобразования номеров примечаний для дальнейшей автоматической генерации сносок в книге (см. соответствующий инструмент выше).
Лучше всего выбрать шаблон для преобразования номеров примечаний в верхнем индексе, отличный от круглых (x) или квадратных [x] скобок, т. к. в тексте могут встречаться пояснения в виде цифр в этих скобках, и при генерации сносок они могут преобразоваться по шаблону! Лучше избрать шаблон в виде фигурных скобок {x}:
Как он работает?
Поиск осуществляется от местоположения видимого курсора, и движется «по кругу». Нажатие кнопки «Найти» выделяет найденные цифры в верхнем индексе. Если эти цифры действительно имеют отношения к номерам примечаний, то для их преобразования есть два выпадающих списка шаблонов и две соответствующие этим спискам кнопки преобразования.
Если включена опция «Искать далее после обработки найденного», то после нажатия одной из кнопок преобразования найденное будет преобразовано по шаблону и будет автоматически найдены другие цифры в верхнем индексе.
После OCR цифрами в верхнем индексе в книге могут обозначаться не только номера примечаний, но и номера сносок в списках текста сносок. Например:

Здесь – и номера примечаний в тексте (сноски), и номера примечаний в списке примечаний – в верхнем индексе. Инструмент найдет все такие номера. И, для каждого из этих 2-х видов цифр в верхнем индексе предусмотрен свой шаблон преобразования и соответствующая ему кнопка преобразования.
Например, для этого текста на картинке, после ручной обработке с шаблонами, показанными на картинке выше результат будет таким:

Теперь такой текст легко может быть использован для работы автоматического генератора сносок (см. выше).
В инструменте предусмотрен выбор поиска либо цифр в верхнем индексе, либо любых символов в верхнем индексе. Последнее часто бывает очень полезно, т. к. после OCR многие цифры примечаний «распознаются, как случайные символы верхнего индекса. Инструмент найдет и их…
4. Нумерация выделенных абзацев
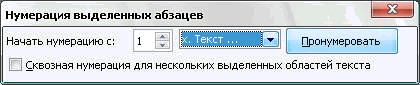
Инструмент написан по следующим причинам:
1. Разработчики OOo Writer очень часто меняют свойства и методы многих объектов и, в частности, нумерованных списков, из-за чего пакет OOoFBTools перестает нормально обрабатывать нумерованные списки.
2. Инструмент автогенерации сносок или гиперссылок не может работать с нумерованными списками.
Поэтому, нумерованные списки можно очень просто заменить на абзацы с нумерацией. Данный инструмент позволяет пронумеровывать либо весь документ, либо 1 или несколько выделенных фрагментов текста. Он игнорирует Таблицы, Текстовые Врезки и Сноски (внизу страницы). Можно задать начальный номер для самого первого абзаца. Можно сделать Сквозную нумерацию для нескольких выделенных областей текста, если включить соответствующую опцию.
Если обрабатываемый абзац – нумерованный список, то автонумерация отключается. Если же этот абзац – простой абзац, то он пронумеровывается без автонумерации. Т. е. в любом случае для обрабатываемых абзацев автонумерация отключается!
Можно задать вид нумерации (полезно для последующей автогенерации сносок или гиперссылок).
Скажу от себя – мне этот инструмент экономит массу времени!

Данный инструмент позволяет делать следующее:
1. Вставлять в заданные абзацы текста символ маркера.
2. Обрабатывать либо выделенные абзацы, либо весь документ.
3. Обрабатывать либо только маркированные абзацы, либо любые не маркированные абзацы, либо – и те и другие. Когда инструмент находит маркированный абзац, он удаляет из него маркер и его признак.
Очень часто после OCR, некоторые виды маркеров в тексте экспортируются в fb2-файл не корректно, что проявляется их «кривым» отображением в читалках. Данный инструмент решает эту проблему.
Экспорт теста с маркерами требует кодировки UTF-8, что влечет за собой увеличение размера результирующего fb2-файла. Используя данный инструмент можно заменить все маркеры на символ маркера, что позволит делать экспорт текста в кодировке Windows-1251 для уменьшения размера fb2-файла. Конечно, при условии, что в тексте отсутствуют Юникодные символы.
Инструмент вызывается либо из меню OOoFBTools. Либо на нажатию кнопки на панели инструментов.
Такая замена пробелов полезна, когда в документе простыми пробелами заданы структуры текста. В fb2-файле простые пробелы после конвертации сохраняются, но читалки и fb2-редакторы "воспринимают" множественные простые пробелы, как один. Тем самым структура текста нарушается. Данный инструмент просто заменяет все простые пробелы на неразрывные (сохраняя их число) либо в выделенных фрагментах текста, либо во всем документе.
Не рекомендуется производить замену во всем документе:
1. Замена происходит медленно – посимвольно. Этот алгоритм вполне достаточен для обработки небольших фрагментов текста. Поэтому для обработки большого объема текста потребуется много времени.
2. Часто множественные пробелы в тексте встречаются из-за неправильного форматирования (обработка текста из Интернета, после OCR и т. д.). Зачастую они не несут никакой смысловой нагрузки. Если же все простые пробелы заменить на неразрывные, то в читалке текст fb2-файла с множественными неразрывными пробелами будет выглядеть некрасиво. Поэтому все множественные простые пробелы лучше заменить на один простой пробел с помощью инструмента Корректор Текста. А потом уже можно задавать нужные вам структуры текста, отбивая уровни пробелами, которые легко и быстро заменяются данным инструментов в выделенном фрагменте текста.
IV. Виртуальные клавиатуры
Иногда требуется в текст документа (корректура, правка после OCR) ввести Unicode символы. Удобнее для этого использовать соответствующие виртуальные клавиатуры:
1. Различные символы (стрелки, ноты…):

2. Математическая:

3. Цифровая:

4. Валютная:

5. Греческая виртуальная клавиатура: