Рассмотрим группу всех имен, впервые появившихся в тексте, в "главе-поколении" с номером Q. Условно назовем эти имена Q-именами, а соответствующие им персонажи Q-персонажами. Количество всех упоминаний, с кратностями, всех этих имен в данной "главе" обозначим через K(Q, Q). Подсчитаем затем, сколько раз эти же имена упомянуты в "главе" с номером Т. Получившееся число обозначим через K(Q, 7).
При этом если одно и то же имя повторяется несколько раз, то есть с кратностью, то все эти упоминания подсчитываются. Построим график, отложив по горизонтали номера "глав", а по вертикали – числа K(Q, T), где номер Q фиксирован, а Г меняется. Для каждого Q мы получаем свой график. Принцип затухания частот тогда формулируется так.
При хронологически правильной нумерации "глав-поколений" каждый график К(Q, T) должен иметь следующий вид. Слева от точки Q график равен нулю, в точке Q – абсолютный максимум графика, потом график постепенно падает, более или менее монотонно затухает (рис. 5.12).
Этот график (на рис. 5.12) мы назовем идеальным.
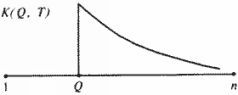
Сформулированный принцип должен быть проверен экспериментально. Если он верен и если "главы" в летописи упорядочены хронологически правильно, то все экспериментальные графики должны быть близки к идеальному. Проведенная экспериментальная проверка полностью подтвердила принцип затухания частот.
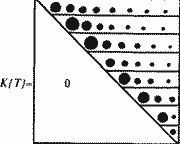
Всего нами было обработано несколько десятков больших исторических текстов. Во всех случаях, когда тексты описывают события эпохи XVI-XX веков, принцип затухания частот подтвердился. Отсюда вытекает методика хронологически правильного упорядочивания "глав-поколений" в тексте, или в наборе текстов, где этот порядок нарушен или неизвестен. Рассмотрим совокупность "глав-поколений" летописи X и занумеруем их в каком-нибудь порядке. Для каждой "главы" X(Q) подсчитаем число K(Q, T) при заданной нумерации "глав". Все числа K(Q, T), при переменных Q и Т, естественно организуются в квадратную матрицу К{T} размера n*n, где n – общее число "глав". В идеальном теоретическом случае частотная матрица К{T} имеет вид, показанный на рис. 5.13.
На рис. 5.13 ниже главной диагонали стоят нули, на главной диагонали расположен абсолютный максимум в каждой строке. Затем каждый график, в каждой строке, монотонно падает, затухает.
Оказывается, аналогичная картина затухания наблюдается и для столбцов матрицы. Это означает, что частота употребления в "главе" X(Q) имен более раннего происхождения "в среднем" тоже падает по мере удаления поколения Т, породившего эти имена, от фиксированного поколения Q.
Для оценки скорости затухания частот удобно пользоваться усредненным графиком
В этой формуле суммирование выполняется по всем парам (Q, Р), для которых разность Р – Q фиксирована и равна Т. Другими словами, график Ксред (T) получается усреднением матрицы К{Т} по ее диагоналям, параллельным главной. Он изображает "усредненную строку" или "усредненный столбец" частотной матрицы. Здесь Т изменяется от 0 до n – 1.
Конечно, экспериментальные графики могут не совпадать с теоретическим.
Если теперь изменить нумерацию "глав" в летописи, то изменятся и числа K(Q, T), поскольку возникает довольно сложное перераспределение "впервые появившихся имен". Следовательно, меняются частотная матрица К{T} и ее элементы. Будем менять порядок "глав" летописи с помощью различных перестановок s.
Каждый раз вычислим новую частотную матрицу K(sT), где sT – новая нумерация, соответствующая перестановке s. Будем искать такой порядок "глав" летописи, при котором все или почти все графики будут иметь вид, показанный на рис. 5.12. В этом случае экспериментальная частотная матрица K{sT} будет наиболее близка к теоретической матрице на рис. 5.13. Тот порядок "глав" летописи, при котором отклонение экспериментальной матрицы от "идеальной" будет наименьшим, и следует признать хронологически правильным и искомым.
Наш метод также позволяет датировать события. Пусть дан какой-то исторический текст Y, о котором известно только, что он рассказывает о неких событиях из эпохи (А, В), уже описанной в тексте X, разбитом на "главы-поколения", причем порядок этих "глав" в летописи X хронологически правилен. Как узнать, какое именно поколение описано в интересующем нас тексте Y? При этом мы хотим использовать только количественные характеристики текстов, не апеллируя к их смысловому содержанию, которое может быть разным или допускать сильно разнящиеся трактовки.
Ответ таков. Присоединим текст Y к совокупности "глав" хроники X, считая при этом Уновой "главой" и приписав ей какой-то номер Q. Затем установим оптимальный, хронологически правильный порядок всех "глав" получившейся "летописи". При этом мы найдем правильное место и для новой "главы" Y. В простейшем случае, построив для нее график K(Q, T), можно добиться, меняя ее положение относительно других "глав", чтобы этот график был как можно ближе к идеальному. То положение, которое Y займет среди других "глав", и следует признать за искомое. Тем самым мы датируем события, описанные в Y.
Методика применима и тогда, когда рассматриваются не все имена, а только одно или несколько имен, например, какие-либо "знаменитые имена". Но в этом случае требуется дополнительный анализ, поскольку уменьшение числа используемых имен делает результаты неустойчивыми.
Метод был проверен на больших текстах с большим числом имен и с заранее известной достоверной датировкой. Во всех этих случаях эффективность метода подтвердилась.
4. Принцип дублирования частот. Метод обнаружения дубликатов
Настоящий метод является в некотором смысле частным случаем предыдущего, но ввиду важности для датировки мы выделили прием обнаружения дубликатов в отдельный раздел. Этот метод был предложен А. Т. Фоменко. Затем он был существенно развит в серии работ совместно с Г. В. Носовским.
Пусть интервал времени (А, В) описан в летописи X, разбитой на "главы-поколения" Х(Т). Пусть они в целом занумерованы хронологически верно, но среди них есть два дубликата, то есть две "главы", говорящие об одном и том же поколении, дублирующие, повторяющие друг друга. Рассмотрим простейшую ситуацию, когда одна и та же "глава" встречается в летописи X ровно два раза, а именно с номером Q и с номером R. Пусть Q меньше R. Наша методика позволяет обнаружить и отождествить эти дубликаты. В самом деле, ясно, что частотные графики K(Q, T) и K(R, T) имеют вид, показанный на рис. 5.14.
Первый график явно не удовлетворяет принципу затухания частот. Поэтому нужно переставить "главы" внутри летописи X, чтобы добиться лучшего соответствия с теоретическим, идеальным графиком. Все числа K(R, T) равны нулю, так как в "главе" X(R) нет ни одного "нового имени" – все они уже появились в X(Q). Ясно, что наилучшее совпадение с идеальным графиком на рис. 5.12 получится тогда, когда мы поместим эти два дубликата рядом или просто отождествим их.
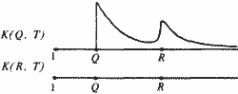
Рис. 5.14
Итак, если среди "глав" летописи, в целом занумерованных правильно, обнаружились две "главы", графики которых имеют приблизительно вид графиков на рис. 5.14, то эти "главы", скорее всего, являются дубликатами. То есть, говорят примерно об одних и тех же исторических событиях, и их следует отождествить. Все сказанное переносится на случай, когда есть несколько дубликатов – три и более.