Воспользуйтесь приведенными ниже командами, чтобы создать пустой файл, инициализировать его для подкачки, а затем добавить в пул подкачки:
# dd if=/dev/zero of=swap_file bs=1024k count=num_mb
# mkswap swap_file
# swapon swap_file
Здесь параметр swap_file задает имя нового файла подкачки, а параметр num_mb — желаемый размер в мегабайтах.
Чтобы удалить раздел или файл подкачки из активного пула ядра, используйте команду swapoff.
4.3.3. Какой объем области подкачки необходим
В свое время, согласно традиционной мудрости Unix, полагали, что всегда следует резервировать для подкачки по меньшей мере в два раза больший объем памяти по сравнению с оперативной. Теперь этот вопрос не столь однозначен, поскольку стали доступны огромные объемы дискового пространства и оперативной памяти, а также изменились способы использования системы. С одной стороны, дисковое пространство настолько обширно, что возникает искушение выделить больше памяти, чем двойной размер оперативной памяти. С другой — вам, вероятно, никогда не придется использовать область подкачки, когда в наличии имеется столько реальной памяти.
Правило о «двойном размере реальной памяти» возникло в то время, когда к одному компьютеру могло быть подключено одновременно несколько пользователей. Не все они могли быть активны, поэтому было удобно переводить в область подкачки те участки памяти, которые были выделены для неактивных пользователей, когда активному пользователю требовалось больше памяти.
Это может по-прежнему быть верным для компьютера с одним пользователем. Если вы запускаете много процессов, как правило, будет неплохо переместить в область подкачки части неактивных процессов или даже неактивные фрагменты активных процессов. Тем не менее, если вы постоянно применяете область подкачки, поскольку многие активные процессы желают сразу же использовать память, вы будете испытывать серьезные сложности с производительностью, так как дисковый ввод-вывод происходит слишком медленно и ему не угнаться за остальной частью системы. Выходы таковы: приобрести дополнительную память или завершить некоторые процессы.
Иногда ядро Linux может перевести в область подкачки какой-либо процесс с целью получения дополнительного дискового кэша. Чтобы это предотвратить, администраторы конфигурируют отдельные системы вообще без области подкачки. Например, высокопроизводительным сетевым серверам не следует использовать область подкачки и по возможности избегать обращения к диску.
примечание
Это опасно выполнять для компьютера общего назначения. Если на компьютере полностью будут исчерпаны оперативная память и область подкачки, ядро Linux запускает подавитель OOM (out-of-memory, нехватка памяти), чтобы прервать процесс и освободить некоторое количество памяти. Вы, безусловно, не захотите, чтобы это случилось с вашими приложениями. С другой стороны, высокопроизводительные серверы содержат сложные системы слежения и выравнивания нагрузки, чтобы никогда не оказаться в опасной зоне.
Из главы 8 вы узнаете подробнее о том, как работает система памяти.
4.4. Заглядывая вперед: диски и пространство пользователя
В относящихся к дискам компонентах системы Unix границы между пространством пользователя и пространством ядра довольно сложно определить. Как вы уже видели, ядро оперирует блочным вводом-выводом от устройств, а инструменты из пространства пользователя способны использовать блочный ввод-вывод с помощью файлов устройств. Тем не менее пространство пользователя, как правило, применяет блочный ввод-вывод только при инициализации таких операций, как создание разделов, файловых систем и области подкачки. В нормальном режиме пространство пользователя задействует только поддержку файловой системы, которая обеспечивается ядром в верхнем слое блочного ввода-вывода. Подобным образом ядро управляет и множеством мелких деталей, когда оно имеет дело с областью подкачки в системе виртуальной памяти.
В следующей части этой главы вкратце рассказано про внутренние части файловой системы Linux. Это более сложный материал, и вам определенно нет необходимости знать его, чтобы продолжить чтение книги. Переходите к следующей главе, чтобы начать изучение процесса загрузки системы Linux.
4.5. Внутри традиционной файловой системы
Традиционная файловая система Unix содержит два основных компонента: пул блоков данных, где можно хранить данные, и базу данных, которая управляет пулом данных. В основу базы данных положена структура данных inode. Дескриптор inode — это набор данных, который описывает конкретный файл, включая его тип, права доступа и (что, возможно, наиболее важно) расположение его данных в пуле данных. Дескрипторы inode распознаются по номерам, перечисленным в соответствующей таблице.
Имена файлов и каталогов также реализованы в виде дескрипторов inode. Дескриптор каталога содержит перечень имен файлов и соответствующих ссылок на другие дескрипторы.
Чтобы привести реальный пример, я создал новую файловую систему, смонтировал ее и сменил каталог на точку монтирования. После этого добавил несколько файлов и каталогов с помощью таких команд (попробуйте выполнить это самостоятельно на флеш-накопителе):
$ mkdir dir_1
$ mkdir dir_2
$ echo a > dir_1/file_1
$ echo b > dir_1/file_2
$ echo c > dir_1/file_3
$ echo d > dir_2/file_4
$ ln dir_1/file_3 dir_2/file_5
Обратите внимание на то, что я создал каталог dir_2/file_5 в виде жесткой ссылки на каталог dir_1/file_3. Это означает, что данные два имени файлов на самом деле представляют один и тот же файл.
Если вы рассмотрите каталоги в этой файловой системе, то ее содержимое выглядело бы так, как показано на рис. 4.4. Реальная разметка файловой системы, как показано на рис. 4.5, не выглядит настолько ясной, как представление на уровне пользователя.
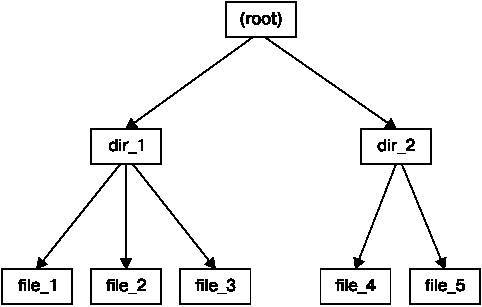
Рис. 4.4. Представление файловой системы на уровне пользователя
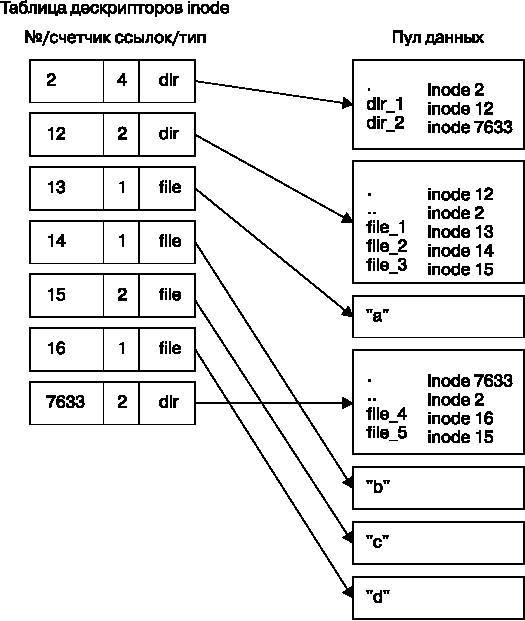
Рис. 4.5. Структура дескрипторов файловой системы, показанной на рис. 4.4
В любой расширенной файловой системе (ext2/3/4) нумерация дескрипторов начинается с 2 — корневого дескриптора inode. Из таблицы дескрипторов на рис. 4.5 можно заметить, что это дескриптор каталога (dir), поэтому можно перейти по стрелке к пулу данных, где вы увидите содержимое корневого каталога: два элемента с именами dir_1 и dir_2, которые соответствуют дескрипторам inode 12 и 7633. Чтобы разобраться с этими элементами, вернитесь в таблицу дескрипторов и посмотрите на любой из них.
Для проверки ссылки dir_1/file_2 в этой файловой системе ядро выполняет следующие действия.
1. Определяет компоненты пути: за каталогом dir_1 следует компонент с именем file_2.
2. Переходит к корневому дескриптору и его данным о каталогах.
3. Отыскивает в данных о каталогах у дескриптора inode 2 имя dir_1, которое указывает на дескриптор с номером 12.
4. Ищет дескриптор inode 12 в таблице дескрипторов и проверяет, является ли он дескриптором каталога.
5. Следует по ссылке дескриптора inode 12 к информации о каталоге (это второй сверху контейнер в пуле данных).
6. Обнаруживает второй компонент пути (file_2) в данных о каталогах дескриптора inode 12. Эта запись указывает на дескриптор inode с номером 14.
7. Отыскивает дескриптор inode 14 в таблице каталогов. Это дескриптор файла.
К этому моменту ядро знает свойства файла и может открыть его, проследовав по ссылке на данные дескриптора inode 14.
Такая система дескрипторов, указывающих на структуры данных каталогов, и структур данных, указывающих на дескрипторы, позволяет создать иерархию файловой системы, к которой вы привыкли. Кроме того, обратите внимание на то, что дескрипторы каталогов содержат записи для текущего каталога (.) и родительского (..), исключая лишь корневой каталог. С их помощью можно легко получить точку отсчета при переходе на уровень выше в структуре каталогов.