Существуют две разновидности статистических методов или тестов, позволяющих делать обобщение или вычислять степень корреляции. Первая разновидность — это наиболее широко применяемые параметрические методы, в которых используются такие параметры, как среднее значение или дисперсия данных. Вторая разновидность — это непараметрические методы, оказывающие неоценимую услугу в том случае, когда исследователь имеет дело с очень малыми выборками или с качественными данными (см. документ Б.1); эти методы очень просты с точки зрения как расчетов, так и применения. Когда мы познакомимся с различными способами описания данных и перейдем к их статистическому анализу, мы рассмотрим обе эти разновидности.
Как уже говорилось, для того чтобы попытаться разобраться в этих различных областях статистики, мы попробуем ответить на те вопросы, которые возникают в связи с результатами того или иного исследования. В качестве примера мы возьмём тот эксперимент, который приведен в главе 3, а именно — изучение влияния потребления марихуаны на глазодвигательную координацию и на время реакции. Методика, используемая в этом гипотетическом эксперименте, а также результаты, которые мы могли бы в нем получить, представлены в дополнении Б.2 [204].
При желании вы можете заменить какие-то конкретные детали этого эксперимента на другие — например, потребление марихуаны на потребление алкоголя или лишение сна, — или, что еще лучше, подставить вместо этих гипотетических данных те, которые вы действительно получили в вашем собственном исследовании. В любом случае вам придется принять «правила нашей игры» и выполнять те расчеты, которые здесь от вас потребуются; только при этом условии до вас «дойдет» существо предмета, если это уже не случилось с вами раньше [205].
Дополнение Б.1. Некоторые основные понятия
Популяция и выборка
Одна из задач статистики состоит в том, чтобы анализировать данные, полученные на части популяции, с целью сделать выводы относительно популяции в целом.
Популяция в статистике не обязательно означает какую-либо группу людей или естественное сообщество; этот термин относится ко всем существам или предметам, образующим общую изучаемую совокупность, будь то атомы или студенты, посещающие то или иное кафе.
Выборка — это небольшое количество элементов, отобранных с помощью научных методов так, чтобы она была репрезентативной, т. е. отражала популяцию в целом.
Данные и их разновидности
Данные в статистике — это основные элементы, подлежащие анализу. Данными могут быть какие-то количественные результаты, свойства, присущие определенным членам популяции, место в той или иной последовательности — в общем любая информация, которая может быть классифицирована или разбита на категории с целью обработки [208].
Построение распределения — это разделение первичных данных, полученных на выборке, на классы или категории с целью получить обобщенную упорядоченную картину, позволяющую их анализировать.
Существуют три типа данных:
1. Количественные данные, получаемые при измерениях (например, данные о весе, размерах, температуре, времени, результатах тестирования и т. п.). Их можно распределить по шкале с равными интервалами.
2. Порядковые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке (1-й…, 7-й…, 100-й…; А, Б, В…).
3. Качественные данные, представляющие собой какие-то свойства элементов выборки или популяции. Их нельзя измерить, и единственной их количественной оценкой служит частота встречаемости (число лиц с голубыми или с зелеными глазами, курильщиков и не курильщиков, утомленных и отдохнувших, сильных и слабых и т. п.).
Из всех этих типов данных только количественные данные можно анализировать с помощью методов, в основе которых лежат параметры (такие, например, как средняя арифметическая). Но даже к количественным данным такие методы можно применить лишь в том случае, если число этих данных достаточно, чтобы проявилось нормальное распределение. Итак, для использования параметрических методов в принципе необходимы три условия: данные должны быть количественными, их число должно быть достаточным, а их распределение — нормальным. Во всех остальных случаях всегда рекомендуется использовать непараметрические методы.
Дополнение Б.2. Влияние потребления марихуаны на глазодвигательную координацию и время реакции (гипотетический эксперимент)
Процедура
На группе из 30 добровольцев — студентов и студенток, курящих обычные сигареты, но не марихуану, — был проведен опыт по изучению глазодвигательной координации. Задача испытуемых заключалась в том, чтобы поражать предъявляемые на дисплее движущиеся мишени, манипулируя подвижным рычагом. Каждому испытуемому были предъявлены 10 последовательностей из 25 мишеней.
Для того чтобы установить исходный уровень, рассчитали среднее число попаданий из 25, а также среднее время реакции для 250 попыток. Далее группа была разделена на две подгруппы как можно более равным образом. Семь девушек и восемь юношей из контрольной группы получили сигарету с обычным табаком и сушеной травой, дым от которой напоминал по запаху дым марихуаны. В отличие от этого семь девушек и восемь юношей из опытной (экспериментальной) группы получили сигарету с табаком и марихуаной. Выкурив сигарету, каждый испытуемый снова был подвергнут тесту на глазодвигательную координацию. (Более подробно этот опыт описан в главе 3).
В табл. Б.2.1 и Б.2.2 представлены средние результаты обоих измерений для испытуемых той и другой группы до и после воздействия.
Таблица Б.2.1. Результативность испытуемых контрольной и опытной групп (среднее число пораженных мишеней из 25 в 10 сериях испытаний)
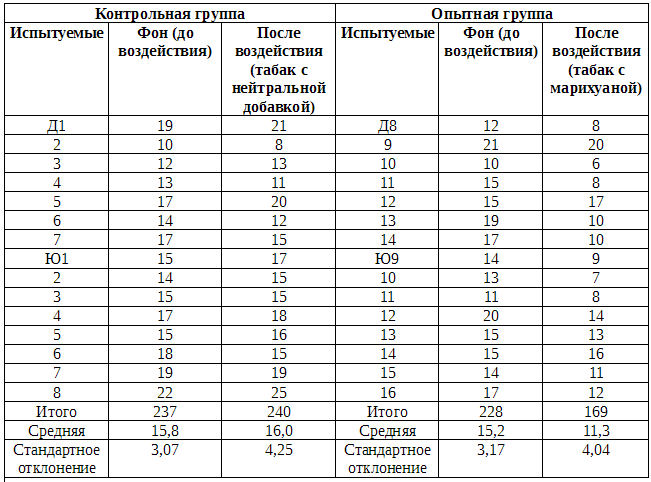
Примечание: девушки: Д1-Д14; юноши: Ю1-Ю16.
Таблица Б.2.2. Время реакции испытуемых контрольной и опытной групп (среднее время 1/10 с в серии из 10 испытаний)
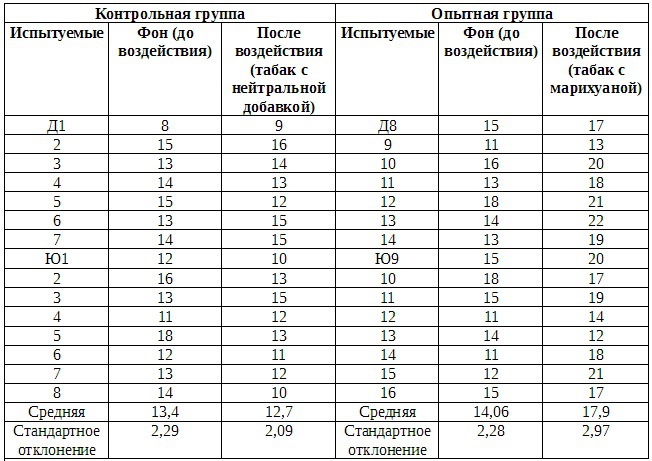
Примечание: девушки: Д1-Д14; юноши: Ю1-Ю16.
Описательная статистика
Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или в эксперименте. Процедуры здесь сводятся к группировке данных по их значениям, построению распределения их частот, выявлению центральных тенденций распределения (например, средней арифметической) и, наконец, к оценке разброса данных по отношению к найденной центральной тенденции.
Группировка данных
Для группировки необходимо прежде всего расположить данные каждой выборки в возрастающем порядке. Так, в нашем эксперименте для переменной «число пораженных мишеней» данные будут располагаться следующим образом:
Контрольная группа
Опытная группа (дополнить цифрами)
204
Важное примечание. В разделах, посвященных описательной и индуктивной статистике, мы будем рассматривать только те данные эксперимента, которые имеют отношение к зависимой переменной «поражаемые мишени». Что касается такого показателя, как время реакции, то мы обратимся к нему только в разделе о вычислении корреляции. Однако само собой разумеется, что уже с самого начала значения этого показателя надо обрабатывать так же, как и переменную «поражаемые мишени». Мы предоставляем читателю заняться этим самостоятельно с помощью карандаша и бумаги.
205
Для того чтобы облегчить задачу, мы советуем вам снять фотокопии таблиц Б.1 и Б.2: тогда на всех этапах рассуждений и расчетов данные будут у вас перед глазами.
207
В отечественной литературе приняты термины соответственно «генеральная совокупность» и «выборочная совокупность». — Прим. перев.
208
Не следует смешивать «данные» с теми «значениями», которые эти данные могут принимать. Для того чтобы всегда различать их, Шатийон (Châtillon, 1977) рекомендует запомнить следующую фразу: «Данные часто принимают одни и те же значения» (так, если мы возьмём, например, шесть данных — 8, 13, 10, 8, 10 и 5, то они принимают лишь четыре разных значения — 5, 8, 10 и 13).